
HQQ
This project extends HQQ to support the mixed quantization (MXQ) method I proposed.
2025-06-16
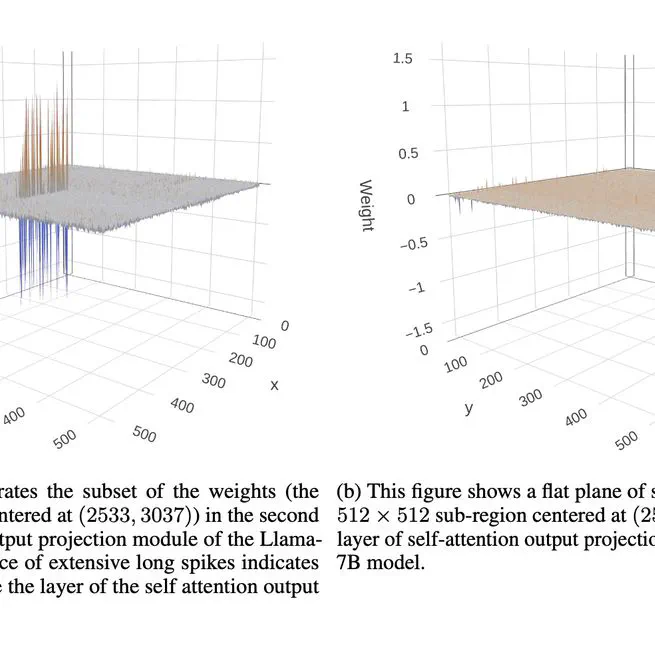
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
This paper leverages activation sensitivity and weight distribution Kurtosis to guide bit budget allocation. The proposed SensiBoost and KurtBoost demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
2025-03-09
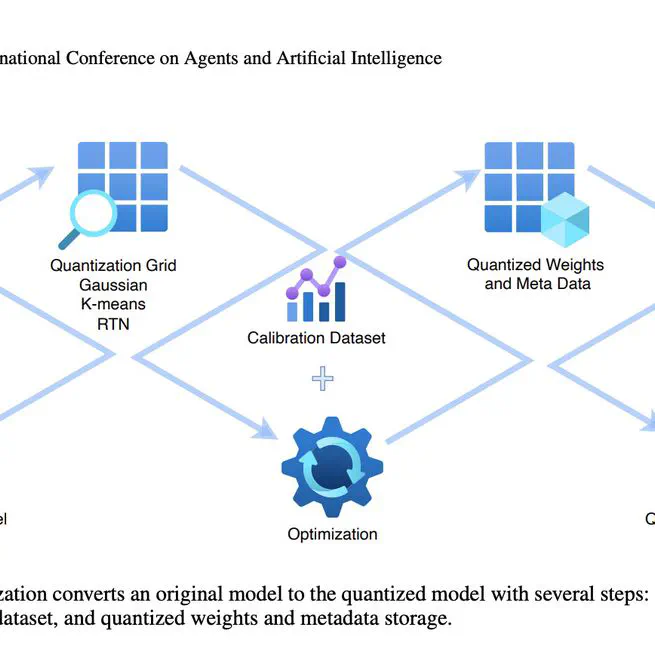
A Mixed Quantization Approach for Data-Free Quantization of LLMs
We propose MXQ to optimise quantization accuracy while enforcing the overall quantization memory consumption. Experiments shows that our method can achieve the 1% accuracy loss goal with additional bit budget or further reduce memory usage on Llama models.
2025-02-23

lm-quant-toolkit
A suite of tools to facilitate large neural network quantization research. It includes a quantization harness to drive quantization experiments on large language models and vision models. It also offers tools to visualize and interpret experiment results.
2024-09-05