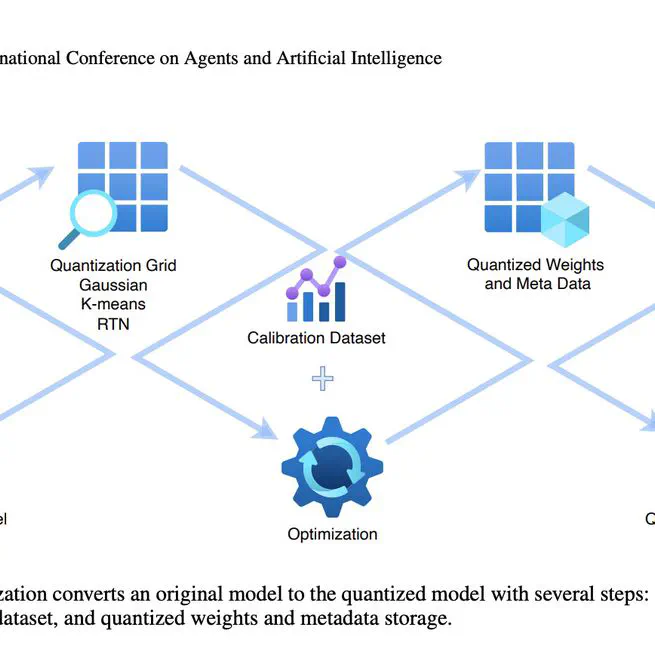
A Mixed Quantization Approach for Data-Free Quantization of LLMs
We propose MXQ to optimise quantization accuracy while enforcing the overall quantization memory consumption. Experiments shows that our method can achieve the 1% accuracy loss goal with additional bit budget or further reduce memory usage on Llama models.
2025-02-23