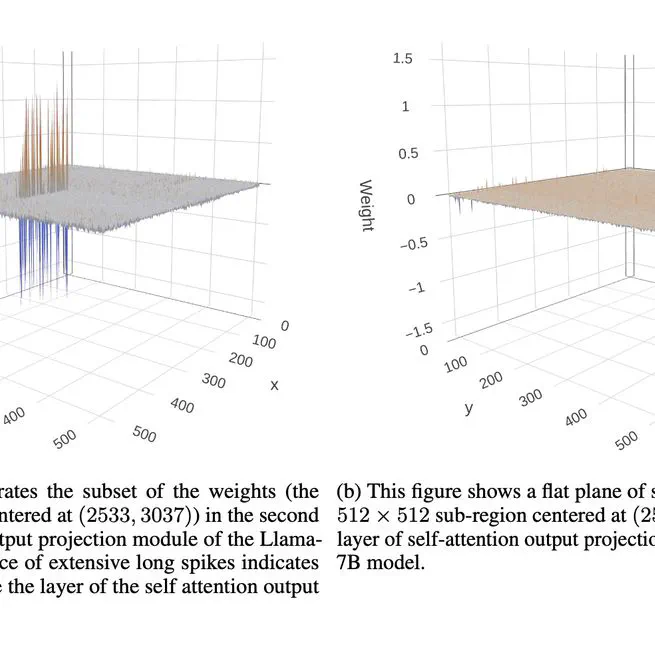
Towards Superior Quantization Accuracy: A Layer-sensitive Approach
This paper leverages activation sensitivity and weight distribution Kurtosis to guide bit budget allocation. The proposed SensiBoost and KurtBoost demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
2025-03-09