Towards Superior Quantization Accuracy: A Layer-sensitive Approach
2025-03-09· ,,,,,·
1 min read
,,,,,·
1 min read
Justin Zhang
Yanbin Liu
Weihua Li
Jie Lv
Xiaodan Wang
Quan Bai
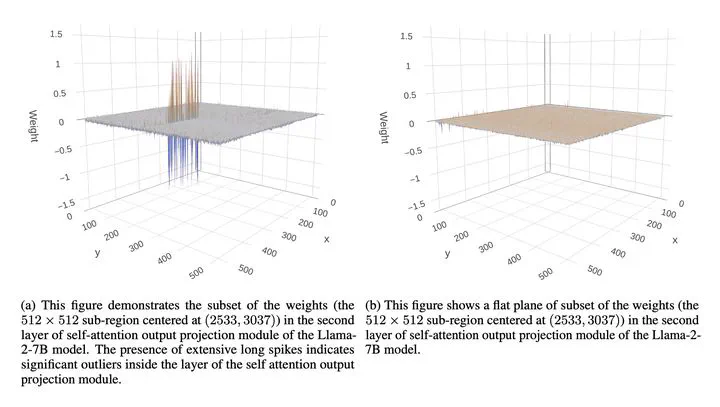 Image credit: arXiv
Image credit: arXivAbstract
Large Vision and Language Models have exhibited remarkable human-like intelligence in tasks such as natural language comprehension, problem-solving, logical reasoning, and knowledge retrieval. However, training and serving these models require substantial computational resources, posing a significant barrier to their widespread application and further research. To mitigate this challenge, various model compression techniques have been developed to reduce computational requirements. Nevertheless, existing methods often employ uniform quantization configurations, failing to account for the varying difficulties across different layers in quantizing large neural network models. This paper tackles this issue by leveraging layer-sensitivity features, such as activation sensitivity and weight distribution Kurtosis, to identify layers that are challenging to quantize accurately and allocate additional memory budget. The proposed methods, named SensiBoost and KurtBoost, respectively, demonstrate notable improvement in quantization accuracy, achieving up to 9% lower perplexity with only a 2% increase in memory budget on LLama models compared to the baseline.
Type
This work is a follow-up research on top of my previous paper on LLMs.
This site hosts an HTML version of the original paper which was converted using
pdf2htmlex. We recommend you read
the HTML version of the paper by clicking VIEW
PAPER as it loads faster and replicates
identical typography quality as its PDF counterpart. If you wish to stick with
the PDF version, click the PDF link
above.